.png)
Synthesizing realistic animations of humans, animals, and even imaginary creatures, has long been a goal for artists and computer graphics professionals. Compared to the imaging domain, which is rich with large available datasets, the number of data instances for the motion domain is limited, particularly for the animation of animals and exotic creatures (e.g., dragons), which have unique skeletons and motion patterns. In this work, we present a Single Motion Diffusion Model, dubbed SinMDM, a model designed to learn the internal motifs of a single motion sequence with arbitrary topology and synthesize motions of arbitrary length that are faithful to them. We harness the power of diffusion models and present a denoising network explicitly designed for the task of learning from a single input motion. SinMDM is designed to be a lightweight architecture, which avoids overfitting by using a shallow network with local attention layers that narrow the receptive field and encourage motion diversity. SinMDM can be applied in various contexts, including spatial and temporal in-betweening, motion expansion, style transfer, and crowd animation. Our results show that SinMDM outperforms existing methods both in quality and time-space efficiency. Moreover, while current approaches require additional training for different applications, our work facilitates these applications at inference time.
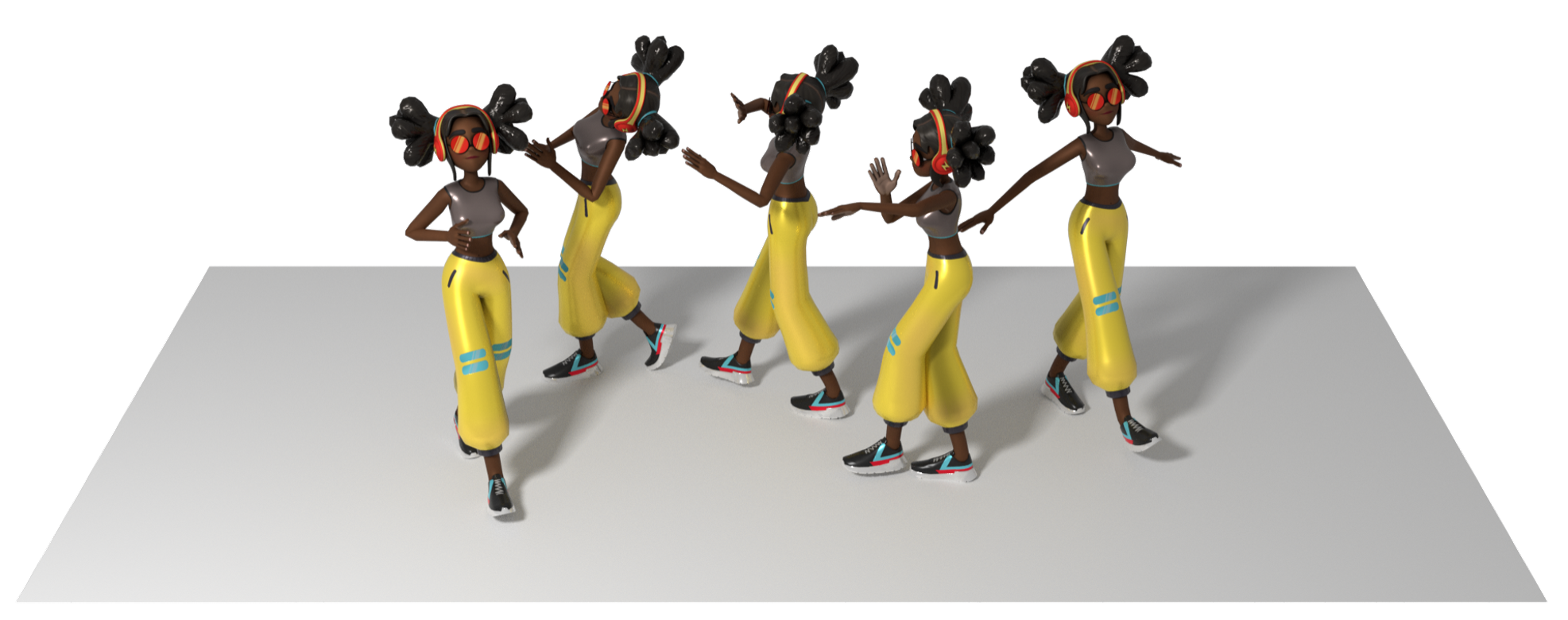
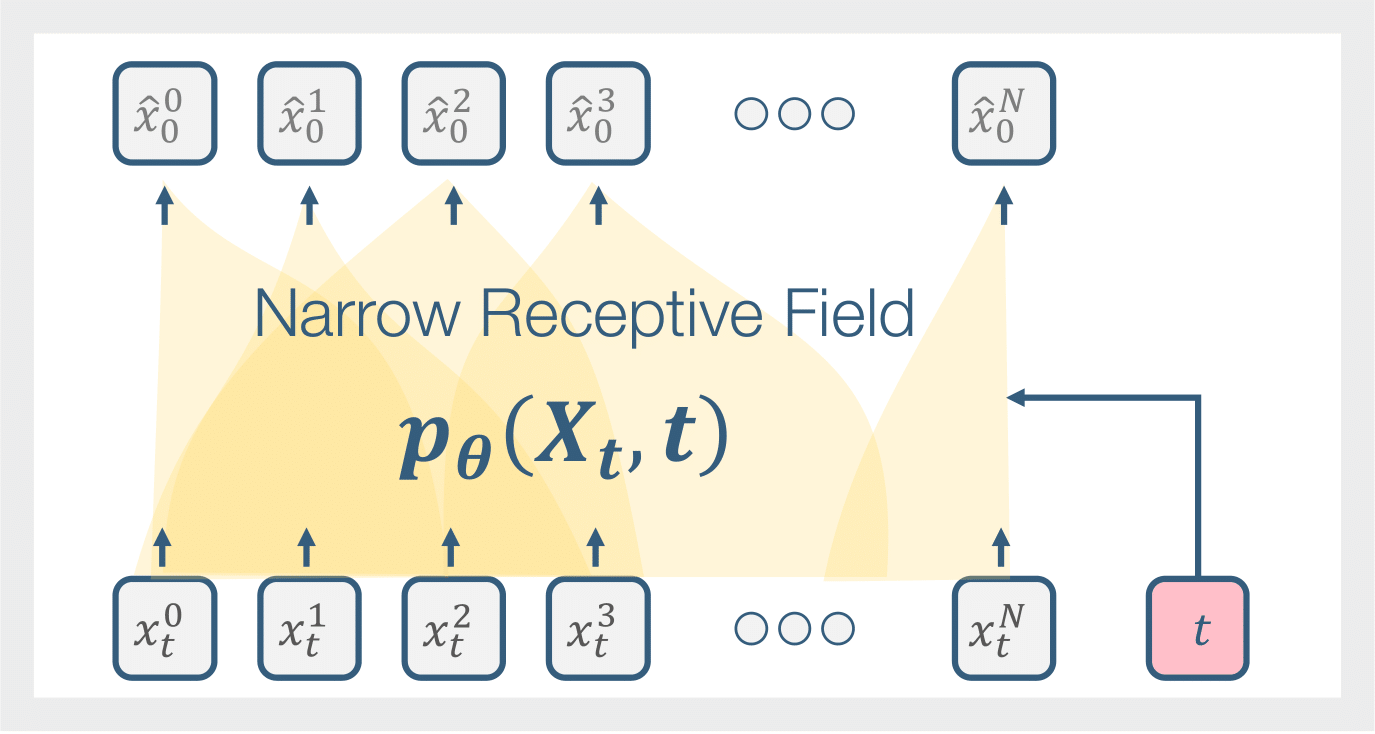
Our goal is to construct a model that can generate a variety of synthesized motions that retain the core motion motifs of a single learned input sequence. To allow training on a single motion, our denoising network is designed such that its overall receptive field covers only a portion of the input sequence. This effectively allows the network to simultaneously learn from multiple local temporal motion segments, as shown below.
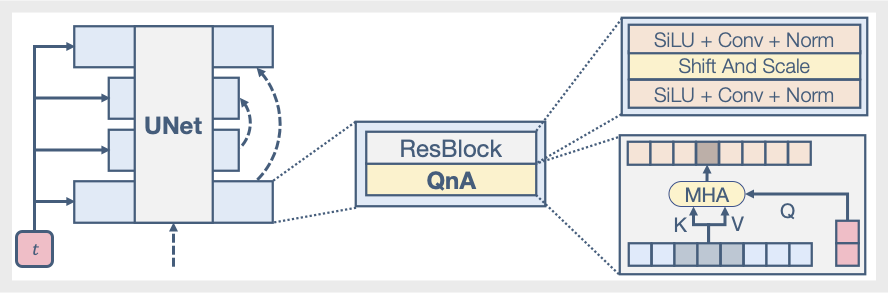
Our network is a shallow UNet, enhanced with a QnA local attention layer.
Our model enables modeling motions of arbitrary skeletal topology, and can handle complex and non-trivial skeletons which often have no more than one animation sequence to learn from.
Although trained on a single sequence, during inference SinMDM can generate a crowd performing a variety of similar motions. For example, our model can generate a diverse crowd based on a hopping ostrich, a jaguar or a breakdancing dragon.
Jaguars
Ostriches
Dragons
A given motion sequence is temporally composed with a synthesized one. Meaning a part of the motion is given, for example the beginning and the end, and the rest is completed by the network. In the examples below, given parts are shaded in gray, and generated parts are full color. Note how the network generates diverse results for the same inputs, and the completed motion naturally matches the given parts even when they are very different.
Warmup to Warmup
Walk to Breakdance to Walk
(Model trained on Breakdance)
Same Motion Prefix
Motion Expansion
Motion composition can also be done spatially by using selected joints as input, and generating the rest. Below we show control over the upper body. The motion of the upper body is determined by a reference motion unseen by the network (Warm-up), and the model synthesizes the rest of the joints according to the learned motion motifs (Walk in cirlce). In the composed result the top body part performs a warm-up activity, and the bottom body part walks in a curvy line.
Upper Body Reference
Training Sequence
Composed Result
In the case of style transfer the model is trained on the style motion, and the content motion, unseen by the network, is adjusted to match the style motion's motifs. Below are examples for transferring "happy" and "crouched" styles to the same walking content motion. Note how both generated results and content motion match in stride pace and rhythm.
"Crouched"ContentResult
"Happy"ContentResult
Our network can synthesize variable length motions, and generate very long animations with no additional training. See below how the input sequence ends long before the generated sequence, which is 60 seconds long.
Original motion
Generated 60 seconds
@inproceedings{raab2024single,
title={Single Motion Diffusion},
author={Raab, Sigal and Leibovitch, Inbal and Tevet, Guy and Arar, Moab and Bermano, Amit H and Cohen-Or, Daniel},
booktitle={The Twelfth International Conference on Learning Representations (ICLR)},
url={https://openreview.net/pdf?id=DrhZneqz4n},
year={2024}
}